17 Predictive Modeling Motivation

Image by Thester11
{kind=link}
17.1 Review
There are three distinct reasons to build a statistical model.
- Summary
- Inference
- Prediction
Summary: Much like a mean can be used to summarize a collection of numbers, a statistical model can be used to summarize relationships between variables.
Inference: With inference, the goal is to use statistics calculated on a sample of data to learn about some unknown parameter from a population. We use data and assumptions for inference. If the assumptions are approximately met, then we can use known sampling distributions to generate test statistics and p-values to make inferences. We can also test formal hypotheses with \(H_0\) as the null hypothesis and \(H_a\) as the alternative hypothesis.
Prediction: With prediction, the goal is make informed and accurate guesses about the value or level of a variable given a set of predictor variables. Unlike inference, which usually focuses on coefficients of predictor variables, the focus here is on the dependent variable.
Consider a population linear regression model:
\[y_i = \beta_0 + \beta_1X_{i1} + \cdot\cdot\cdot + \beta_pX_{ip} + \epsilon_i\]
and an estimated linear regression model
\[\hat{y_i} = \hat\beta_0 + \hat\beta_1x_{i1} + \cdot\cdot\cdot + \hat\beta_px_{ip} \tag{17.1}\]
We can use Equation 17.1 for all three motivations.
- Equation 17.1 is a model of the conditional mean of \(y\), which is a statistical summary.
- Equation 17.1 allows us to make inference about \(\beta_j\) using \(\hat\beta_j\).
- Equation 17.1 allows us to make predictions, \(\hat{y_i}\), given \(\vec{x_i}\).
The same statistical model can summarize, be used for inference, and make valid and accurate predictions. However, the optimal model for one motivation is rarely best for all three motivations. Thus, it is important to clearly articulate the motivation for a statistical model before picking which tools and diagnostics to use.
17.2 Problem Structure
There are many policy applications where it is useful to make accurate predictions on “unseen” data. Unseen data means any data not used to develop a model for predictions.
The broad process of developing models to make predictions of a pre-defined variable is predictive modeling or supervised machine learning. The narrower process of developing a specific model with data is called fitting a model, learning a model, or estimating a model. The pre-defined variable the model is intended to predict is the outcome variable and the remaining variables used to predict the outcome variable are predictors.1
In most applications we have modeling data that include the outcome of interest and implementation data that do not include the outcome of interest. Our objective is to fit, or estimate, some \(\hat{f}(\vec{x})\) using the modeling data to predict the missing outcome in the implementation data.
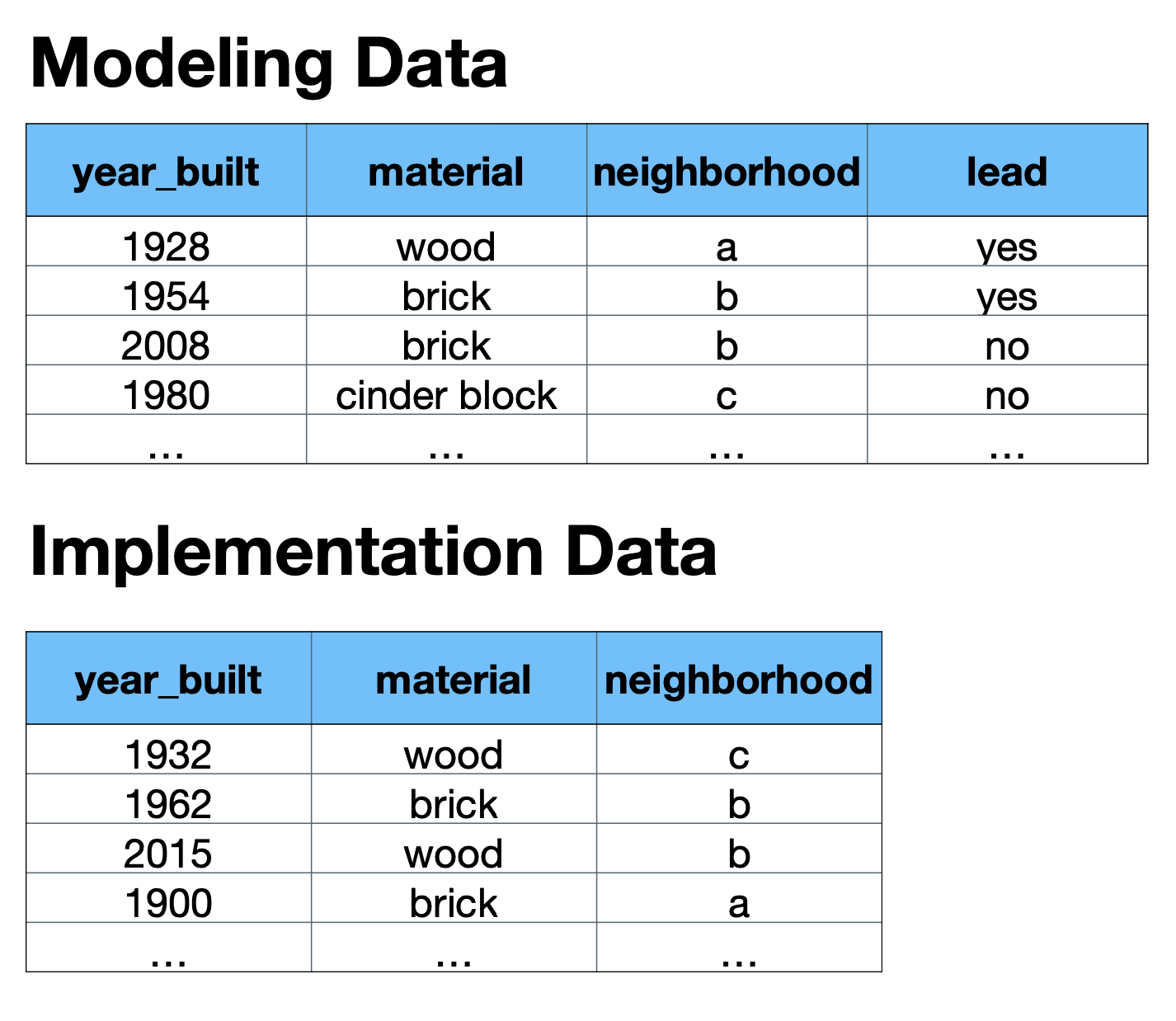
Modeling data contain the outcome variable of interest, and predictors for fitting models to predict the outcome variable of interest.
Modeling data are often historical data or high-cost data.
Implementation data contain predictors for predicting the outcome of interest but don’t necessarily contain the outcome of interest.
The implementation data needs to contain all of the predictors used in the modeling data, and the implementation data can’t be too different from the modeling data.

Our fitted models never perfectly predict the outcome, \(y\). Therefore, we end up with \(y = \hat{f}(\vec{x}) + \epsilon\). A major effort in predictive modeling is improving \(\hat{f}(\vec{x})\) to reduce \(\epsilon\).
17.3 Example: Marbles
17.3.1 Implementation Data
| Size | Color |
|---|---|
| Small | ? |
| Big | ? |
| Big | ? |
17.3.2 Modeling Data
| Size | Color |
|---|---|
| Small | Red |
| Small | Red |
| Small | Red |
| Small | Red |
| Small | Blue |
| Big | Red |
| Big | Blue |
| Big | Blue |
| Big | Blue |
| Big | Blue |
17.3.3 Predictive Model
How can we predict color in the implementation data?
A simple decision tree works well here! Predictive modeling! Machine learning!
- If a marble is small, then predict Red
- If a marble is big, then predict Blue
Most predictive modeling is repeating this type of learning in higher-dimensional applications where it is tougher to see the model with a glance.
17.4 Applications
Predictive modeling has many applications in public policy. Predictive models can be used to improve the allocation of scarce resources, scale survey responses or hand-labelled data sets, and forecast or nowcast.
17.4.1 Targeting Interventions
Using predictive modeling to target the person, household, or place most in need of a policy intervention. Effective targeting can maximize the impact of a limited intervention.
17.4.2 Amplified Asking
Amplified asking (Salganik 2018) uses predictive modeling trained on a small amount of survey data from one data source and applies it to a larger data source to produce estimates at a scale or geographic granularity not possible with either data set on its own.
17.4.3 Scaled Labeling
The process of labeling a subset of data and then using predictive models to label the full data.
This is most effective when labeling the data is time consuming or expensive.
17.4.4 Forecasting and Nowcasting
A forecast attempts to predict the most-likely future. A nowcast attempts to predict the most-likely present in situations where information is collected and reported with a lag.
17.4.5 Imputation
Broadly, imputation is the task of using models to assign, or impute, missing values in some dataset. Broadly, imputation can be used for a variety of applications including trying to reduce the consequences of omitted variable bias, generating synthetic data to minimize disclosure risks, and data fusion. Amplified asking and scaled labeling are also examples of imputation tasks.
17.5 Case Studies
17.5.1 Preventing Lead Poisoning
Consider “Predictive Modeling for Public Health: Preventing Childhood Lead Poisoning” by Potash et al. (2015).
The authors use historical data in Chicago from home lead inspectors and observable characteristics about homes and neighborhoods to predict if homes contain lead.
- Motivation: Lead poisoning is terrible for children, but Chicago has limited lead inspectors.
- Implementation data: Observed characteristics about homes and neighborhoods in Chicago.
- Modeling data: Historical characteristics about homes and neighborhoods in Chicago and results from home lead inspections.
- Objective: Predict the probability of a home containing lead. 1. Prioritize sending inspectors to the homes of the most at-risk children before the child suffers from elevated blood lead level (BLL). 2. Create a risk score for children that can be used by parents and health providers.
- Tools: Cross validation and regularized logistic regression, linear SVC, and Random Forests.
- Results: The precision of the model was two to five times better than the baseline scenario of randomly sending inspectors. The advantage faded over time and in situations where more inspectors were available.
17.5.2 Measuring Wealth in Rwanda
Consider “Calling for Better Measurement: Estimating an Individual’s Wealth and Well-Being from Mobile Phone Transaction Records” by Blumenstock (n.d.) and “Predicting poverty and wealth from mobile phone metadata” by Blumenstock, Cadamuro, and On (2015).
- Motivation: Measuring wealth and poverty in developing nations is challenging and expensive.
- Implementation data: 2005-2009 phone metadata from about 1.5 million phone customers in Rwanda.
- Modeling data: A follow-up phone stratified survey of 856 phone customers with questions about asset ownership, home ownership, and basic welfare indicators linked to the phone metadata.
- Objective: Use the phone metadata to accurately predict variables about asset ownership, home ownership, and basic welfare indicators. One of their outcomes variables is the first principal component of asset variables.
- Tools: 5-fold cross-validation, elastic net regression and regularized logistic regression, deterministic finite automation.
- Results: The results in the first paper were poor, but follow-up work resulted in models with AUC as high as 0.88 and \(R^2\) as high as 0.46.
17.5.3 Collecting Land-Use Reform Data
Consider “How Urban Piloted Data Science Techniques to Collect Land-Use Reform Data” by Zheng (2020).
- Motivation: Land-use reform and zoning are poorly understood at the national level. The Urban Institute set out to create a data set from newspaper articles that reflects land-use reforms.
- Implementation data: About 76,000 newspaper articles
- Modeling data: 568 hand-labelled newspaper articles
- Objective: Label the nature of zoning reforms on roughly 76,000 newspaper articles.
- Tools: Hand coding, natural language processing, cross-validation, and random forests
- Results: The results were not accurate enough to treat as a data set but could be used to target subsequent hand coding and investigation.
17.5.4 Google Flu Trends
Consider the high-profile Google Flu Trends model by Ginsberg et al. (2009).
- Motivation: The CDC tracks flu-like illnesses and releases data on about a two-week lag. Understanding flu-like illnesses on a one-day lag can improve public health responses.
- Implementation data: Real-time counts of Google search queries.
- Modeling data: 2003-2008 CDC data about flu-like illnesses and counts for 50 million of the most common Google search queries in each state.
- Objective: Predict regional-level flu outbreaks on a one-day lag using Google searches to make predictions.
- Tools: Logistic regression and the top 45 influenza related illness query terms.
- Results: The in-sample results were very promising. Unfortunately, the model performed poorly when implemented. Google implemented Google Flu Trends but later discontinued the model. The two major issues were:
- Drift: The model decayed over time because of changes to search
- Algorithmic confounding: The model overestimated the 2009 flu season because of fear-induced search traffic during the Swine flu outbreak
The are many names for outcome variables including target and dependent variable. There are many names for predictors including features and independent variables.↩︎