There exist useful alternative formats to tidytext for storing text information. Different applications use different formats.
TipDocument-Term Matrix
A matrix where rows are documents, columns are words, and cells are counts. A document-term matrix is typically sparse.
TipOne-row-per document
A data frame with a column where each cell is the entire text for a document. This is useful for predictive modeling.
Example 01
library(tidyverse)library(tidytext)theme_set(theme_minimal())example_doc <-tribble(~document, ~word, ~n,"a", "apple", 3,"a", "orange", 2, "a", "banana", 1,"b", "apple", 2, "b", "banana", 3 )document_term_matrix <- example_doc |>cast_dtm(document = document, term = word, value = n)# document term matrices are large and typically print like thisdocument_term_matrix
<<DocumentTermMatrix (documents: 2, terms: 3)>>
Non-/sparse entries: 5/1
Sparsity : 17%
Maximal term length: 6
Weighting : term frequency (tf)
# here we can see the actual matrixas.matrix(document_term_matrix)
Terms
Docs apple orange banana
a 3 2 1
b 2 0 3
26.1.2library(broom)
library(broom) contains three functions for tidying up the output of models in R. Most models work with library(broom) including lm(), glm(), and kmeans().
glance() Returns one row per model.
tidy() Returns one row per model component (i.e. regression coefficient or cluster).
augment() Returns one row per observation in the model data set.
26.1.3 Example 02
library(broom)cars_lm <-lm(dist ~ speed, data = cars)# one row for the modelglance(cars_lm)
The algorithmic grouping or clustering of documents using features extracted from the documents. This includes unsupervised classification of documents into meaningful groups.
TipTopic modeling
The unsupervised clustering, or grouping, of text documents based on their content.
Alena Stern used Latent Dirichlet Allocation (LDA) to sort 110,063 public records requests into 60 topics (blog)
Pew Research used unsupervised and semi-supervised methods to create topic models of open-ended text responses about where Americans find meaning in their lives. (blog)
Leveraging what we already know, we can use K-means clustering on a term-document matrix to cluster documents. This approach has two shortcomings and one advantage.
It takes a lot of work to summarize documents that are grouped with K-means clustering.
K-means clustering creates hard assignments. Each observation belongs to exactly one cluster.
K-means clustering uses Euclidean distance, which is relatively simple when working with text
TipSoft assignment
Observations are assigned to each cluster or group with probabilities or weights. For example, observation 1 belongs to Group A with 0.9 probability and Group B with 0.1 probability.
We will focus on a topic modeling algorithm called Latent Dirichlet Allocation (LDA). Non-negative matrix factorization is a different popular algorithm that we will not discuss.
TipLatent Dirichlet Allocation (LDA)
A probabilistic topic model where each document is a mixture of topics and each topic is a mixture of words.
26.2.1 LDA as a generative model
LDA is a generative model. The model describes how the documents in a corpus were created. LDA relies on the bag-of-words assumption.
TipBag-of-words assumption
Disregard the grammar and order of words.
According to the model, any time a document is created:
Choose the length of the document, \(N\), from a probability distribution
Randomly choose topic probabilities for a document
For each word in the document
Randomly choose a topic
Randomly choose a word conditioned on the topic from a.
26.2.2 Example 03
Let’s demonstrate generating a document using this model. First, let’s define two topics. topic1 is about the economy and topic2 is about sports. Note that “contract” and “union” are in both topics:
Next, randomly sample a document length. In this case, we will use the Poisson distribution, which returns non-negative integers. We use _i to note that this is for the \(i^{th}\) document.
Each document will have a document-specific topic probability distribution. We use the Dirichlet distribution to generate this vector of probabilities. The Dirichlet distribution is a multivariate beta distribution. The beta distribution returns random draws between 0 and 1 and is related to the standard uniform distribution.
We have now generated a document that is a mixture of the two topics. It’s more sports than economics, but contains both topics.
The topics are also mixtures of words. “Basketball” only shows up in the sports topic but “union” and “contract” are in both topics. When used in practice, LDA generally involves more words, more topics, and more documents.
26.2.3 LDA and inference
LDA is based on this data generation process, but we don’t know the document-specific topic distribution or the topics for the individual words. Thus, LDA is a statistical inference procedure where we try to make inferences about parameters. In other words, we are trying to reverse engineer the generative process outlined above using a corpus of documents. In practice, we don’t care about the length of the document, so we can ignore step 1.
The optimization for LDA is similar to the optimization for K-means clustering. First, every word in the corpus is randomly assigned a topic. Then, the model is optimized through a two-step process based on expectation maximization (EM), which is the same optimization algorithm used with K-means clustering:
Find the optimal posterior topic distribution for each document (this is \(\theta\) indirectly) assuming the prior parameters are known
Find the optimal prior parameters assuming the posterior topic distribution for each document is known
Repeat steps 1. and 2. until some topping criterion is reached
26.2.4 Example 04
Let’s consider the executive orders data set. We repeat the pre-processing from the past example but with even more domain-specific stop words. Note: this example builds heavily on Chapter 6 in Text Mining With R.
library(tidyverse)library(tidytext)library(SnowballC)library(topicmodels)# load one-row-per-line data ----------------------------------------------eos <-read_csv(here::here("data", "executive-orders.csv"))eos <-filter(eos, !is.na(text))# tokenize the text -------------------------------------------------------tidy_eos <- eos |>unnest_tokens(output = word, input = text)# create domain-specific stop wordsdomain_stop_words <-tribble(~word, "william","clinton","george","bush", "barack","obama", "donald","trump","joseph","biden","signature","section","authority","vested","federal","president","authority","constitution","laws","united","states","america","secretary","assistant","executive","order","sec","u.s.c","pursuant","act","law") |>mutate(lexicon ="custom")stop_words <-bind_rows( stop_words, domain_stop_words)# remove stop words with anti_join() and the stop_words tibbletidy_eos <- tidy_eos |>anti_join(stop_words, by ="word") # remove words that are entirely numberstidy_eos <- tidy_eos |>filter(!str_detect(word, pattern ="^\\d")) # stem words with wordStem()tidy_eos <- tidy_eos |>mutate(stem =wordStem(word))
Next, we convert the tidytext executive orders into a document-term matrix with cast_dtm().
tidy_eos_count <- tidy_eos |>count(president, executive_order_number, stem) eos_dtm <- tidy_eos_count |>cast_dtm(document = executive_order_number, term = stem, value = n)
Once we have a document-term matrix, implementing LDA is straightforward with LDA(), which comes from library(topicmodels). We must predetermine the number of groups with k and we set the seed because the algorithm is stochastic (not deterministic).
eos_lda <- eos_dtm |>LDA(k =22, control =list(seed =20220417))
Note: I chose 22 topics using methods outlined in the appendix.
Interpreting an estimated LDA model is the tricky work. We will do this by looking at
Each topic as a mixture of words
Each document as a mixture of topics
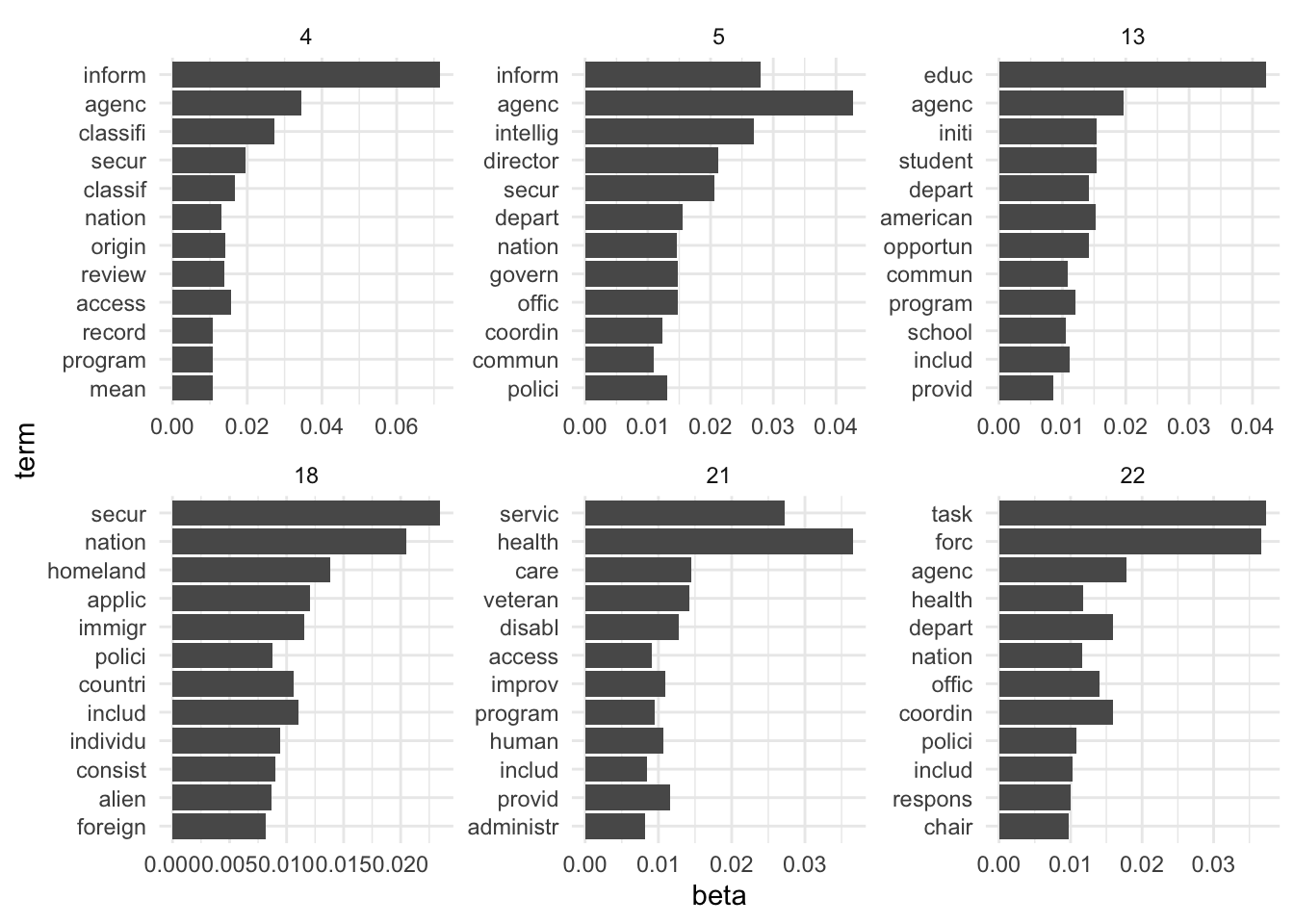
Word topic probabilities
With LDA, each topic is a mixture of words. The model returns estimated parameters called \(\beta\). A \(\beta\) represents the estimated probability of a specific word being generated from a particular topic. We can extract \(\beta\) from the output of LDA() with tidy().
# pick 6 random topics for visualizationrandom_topics <-sample(1:22, size =6)top_beta |>filter(topic %in% random_topics) |>mutate(term =reorder(term, beta)) |>ggplot(aes(x = beta, y = term)) +geom_col() +facet_wrap(~ topic, scales ="free")
Document-topic probabilities
With LDA, each document is a mixture of topics The model returns estimated parameters called \(\gamma\). A \(\gamma\) represents the estimated proportion of words from a specific document that come from a particular topic.
LDA isn’t perfect. It can result in topics that are too broad (what Patrick van Kessel calls “undercooked”) or topics that are too granular (what van Kessel calls “overcooked”).
In a related blog, van Kessel discusses using a semi-supervised algorithm called CorEx to resolve some of these challenges. With semi-supervised learning, the analyst can provide anchor terms that help the algorithm generate topics that are better cooked than with unsupervised learning.
26.3 Text Classification (supervised machine learning)
Sometimes it is useful to create a predictive model that uses text to predict a pre-determined set of labels. For example, if you have a historical corpus of labeled documents and you want to predict labels for new documents. For example, if you have a massive corpus set with a hand-labeled random sample of documents and you want to scale those labels to all documents.
Fortunately, we can use all of the library(tidymodels) tools we already learned this semester. We simply need a way to convert unstructured text into predictors, which is simple with library(textrecipes).
26.4library(textrecipes)
library(textrecipes) augments library(recipes) with step_*() functions that are useful for supervised machine learning with text data.
step_tokenize() Create a token variable from a character predictor.
step_tokenfilter() Remove tokens based on rules about the frequency of tokens.
step_tfidf() Create multiple variables with TF-IDF.
step_ngram() Create a token variable with n-grams.
step_stem() Stem tokens.
step_lemma() Lemmatizes tokens with library(spacyr).
step_stopwords() Remove stopwords.
26.4.1 Example 05
Consider the Federalist Papers data set we used in the earlier class notes. After loading the data, the data are in one-row-per-line format. This is the format that we tidied with unnest_tokens().
# A tibble: 18,265 × 3
text paper_number author
<chr> <int> <chr>
1 "THE FEDERALIST PAPERS THE FEDERALIST PAPERS THE FEDERAL… 1 hamil…
2 " 1 FEDERALIST No" 2 jay
3 " 1 FEDERALIST No" 3 jay
4 " 1 General Introduction General Introduction General… 3 jay
5 " Saturday, October 27, 1787 For the Independent Journal" 3 jay
6 " Saturday, October 27, 1787 For the Independent Journal" 3 jay
7 " Saturday, October 27, 1787 HAMILTON HAMILTON HAM… 3 jay
8 " The subject speaks its Constitution for the United Sta… 3 jay
9 " The subject speaks its Constitution for the United Sta… 3 jay
10 " The subject speaks its own importance; comprehending i… 3 jay
# ℹ 18,255 more rows
Predictive modeling uses a slightly different data format than tidytext. We want each row in the data to correspond with the observations we are using for predictions. In this case, we want one row per Federalist paper.
We can use nest() and paste() to transform the data into this format.
fed_papers <- fed_papers |>group_by(paper_number) |>nest(text = text) |># paste individual lines into one row per documentmutate(text =map_chr(.x = text, ~paste(.x[[1]], collapse =" "))) |>ungroup() |># remove white spacesmutate(text =str_squish(str_to_lower(text)))fed_papers
# A tibble: 255 × 3
paper_number author text
<int> <chr> <chr>
1 1 hamilton "the federalist papers the federalist papers the feder…
2 2 jay "1 federalist no"
3 3 jay "1 federalist no 1 general introduction general introd…
4 4 jay "federalist no"
5 5 jay "2 federalist no"
6 6 hamilton "2 federalist no 2 concerning dangers from foreign for…
7 7 hamilton "\" publius publius publius federalist no"
8 8 hamilton "3 federalist no"
9 9 hamilton "3 federalist no 3 the same subject continued (concern…
10 10 madison "publius publius publius federalist no"
# ℹ 245 more rows
Let’s prep() and bake() a recipe. We want to use recipes because most of these step_*() functions are data dependent and need to be repeated during resampling.
Let’s finish with an example using the executive orders data set. The data contain executive orders for presidents Clinton, Bush, Obama, Trump, and Biden. We will build a model that predicts the party of the president associated with each executive order. Even though we know the party, we can
predict the party of future executive orders
see which predictors are most predictive of party
First, we need to load and pre-process the data.
eos <-read_csv(here::here("data", "executive-orders.csv"))# remove empty rowseos <-filter(eos, !is.na(text))# remove numberseos <- eos |>mutate(text =str_remove_all(text, "\\d")) |>mutate(text =str_remove_all(text, "``''")) |>mutate(text =str_squish(text))# combine rows into one row per documenteos <- eos |>group_by(executive_order_number) |>nest(text = text) |>mutate(text =map_chr(.x = text, ~paste(.x[[1]], collapse =" "))) |>ungroup()# label the party of each executive orderrepublicans <-c("bush", "trump")eos_modeling <- eos |>mutate(party =if_else(condition = president %in% republicans, true ="rep", false ="dem" ) ) |># we can include non-text predictors but we drop predictors that would be too# useful (i.e. dates align with individual presidents)select(-president, -signing_date, -executive_order_number)
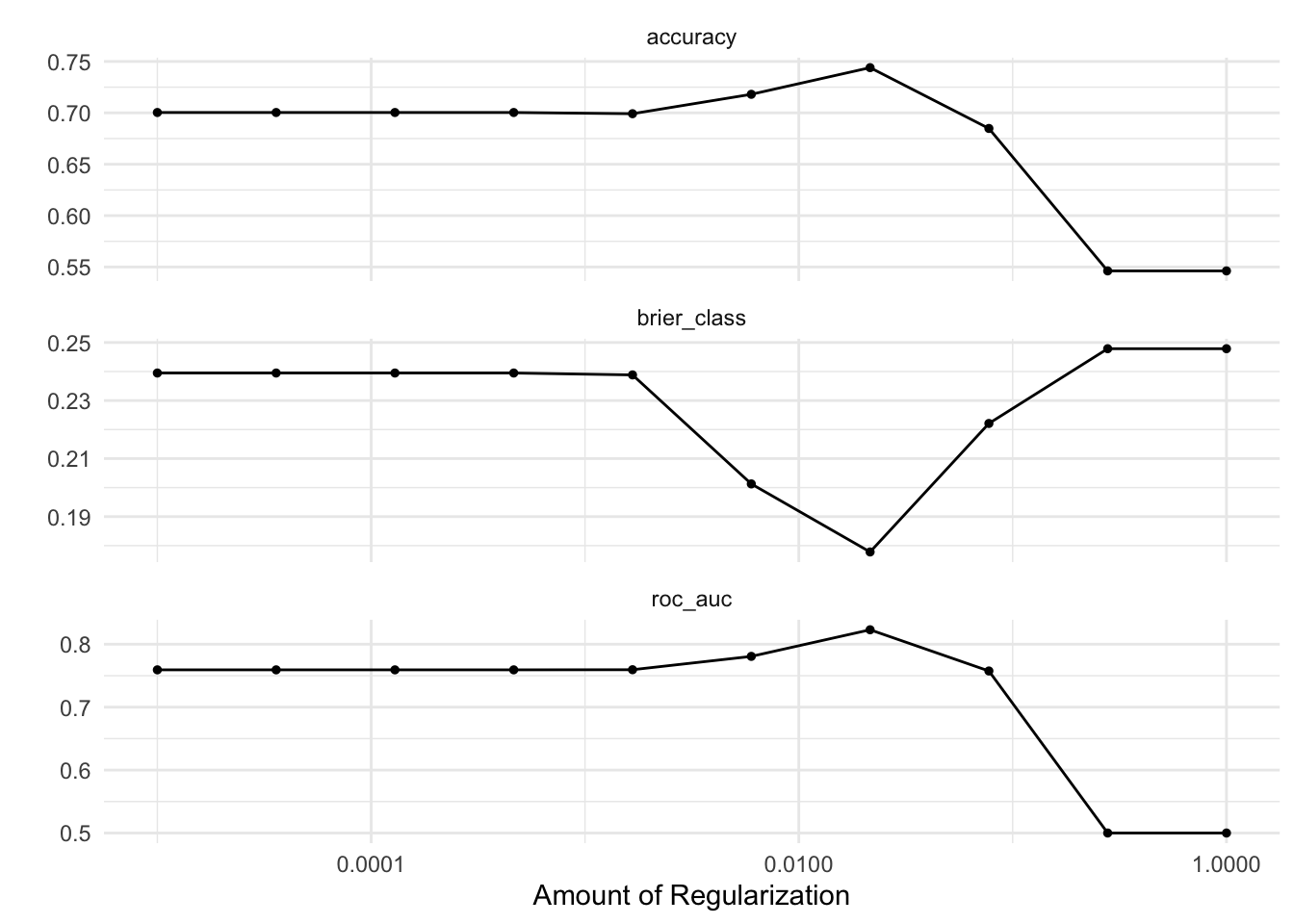
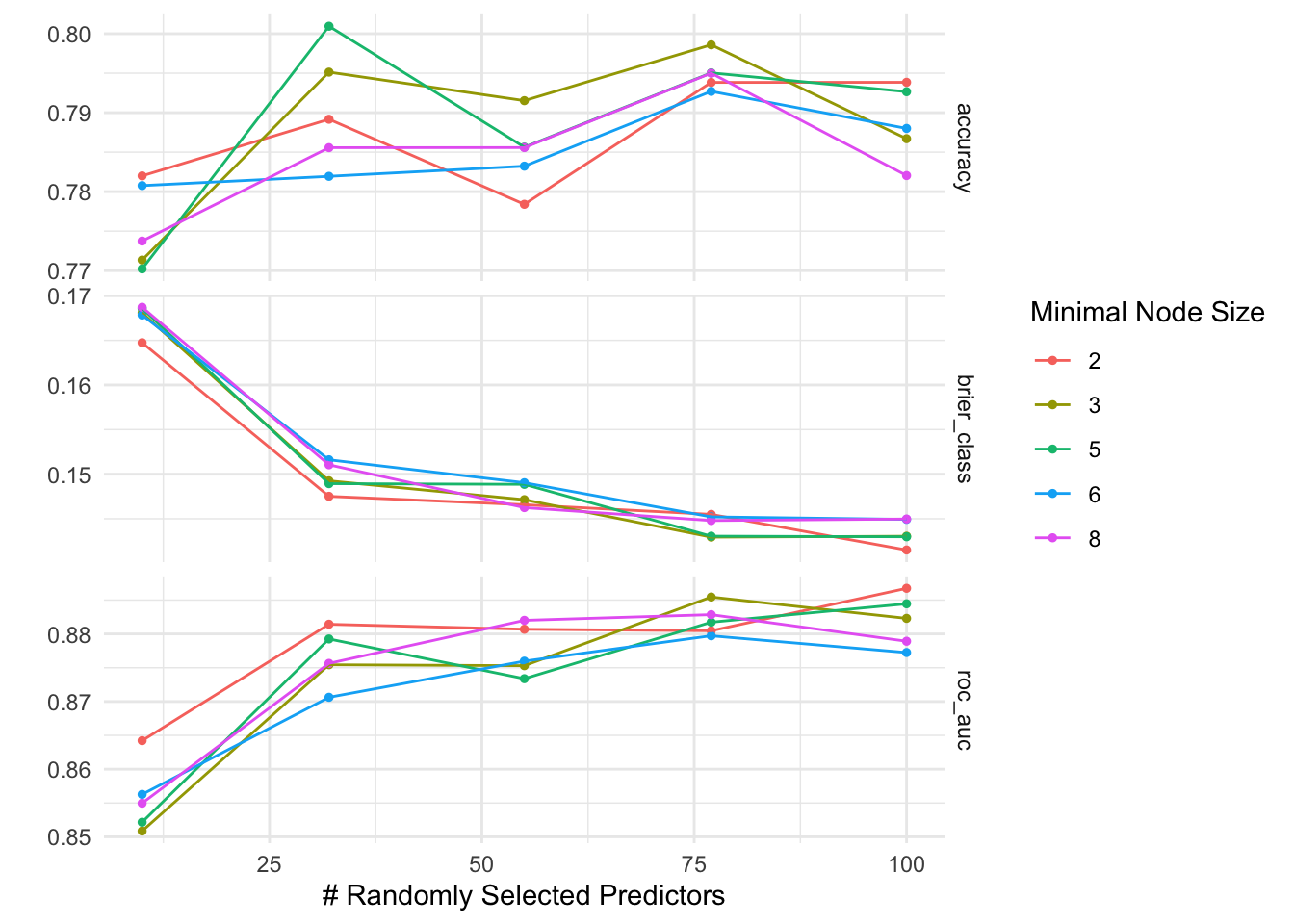
26.4.3 Logistic LASSO regression
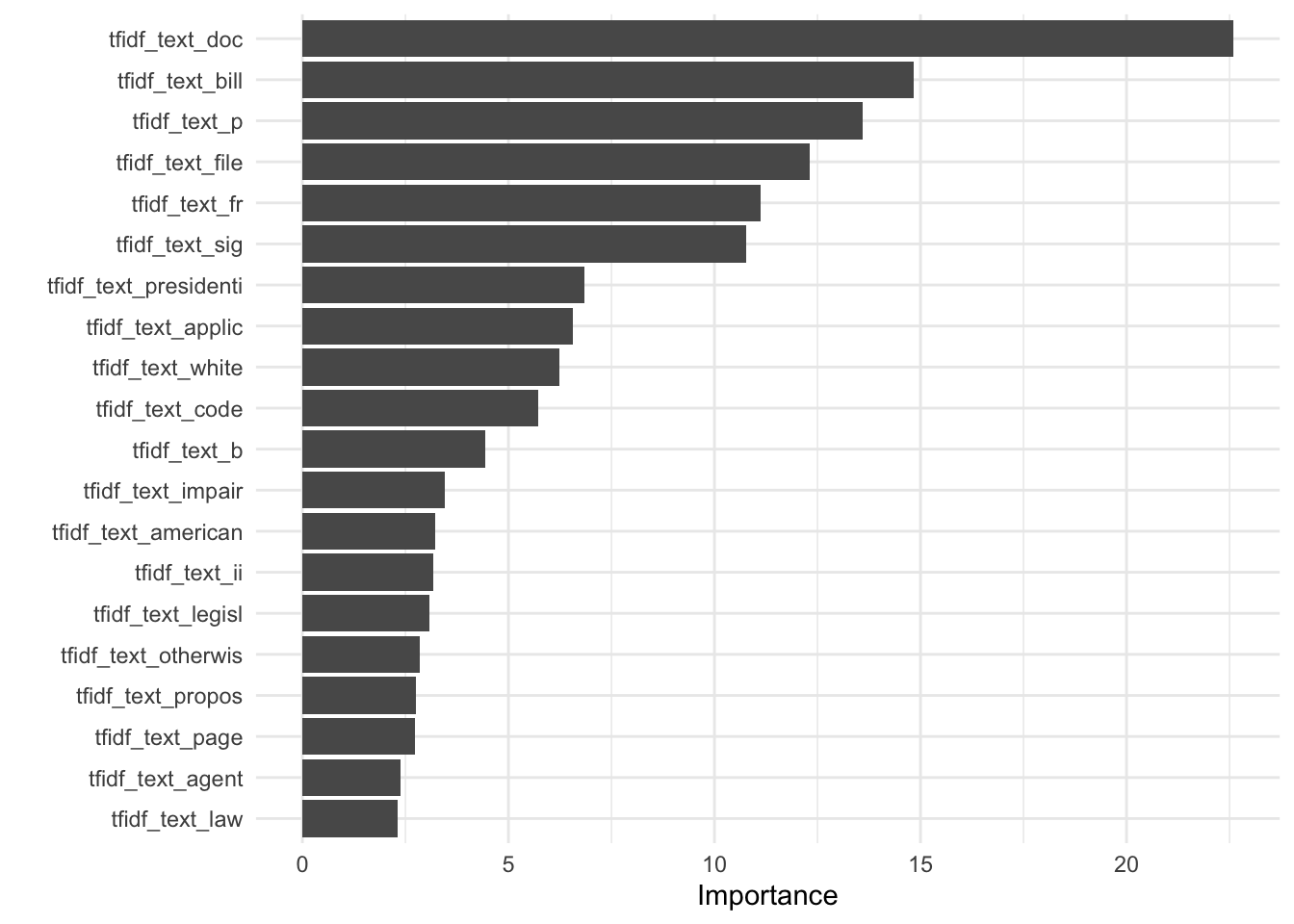
We will test a parametric (logistic LASSO regression) and a non-parametric(random forest) to predict the party using only the text of the executive orders. We will use cross-validation for model selection.
library(tidymodels)library(textrecipes)library(vip)# create a training/testing splitset.seed(43)eos_split <-initial_split(eos_modeling, strata = party)eos_train <-training(eos_split)eos_test <-testing(eos_split)# set up cross validationset.seed(34)eos_folds <-vfold_cv(eos_train, strata = party)
Next, let’s create a recipe that will be used by both models.
eos_rec <-recipe(party ~ text, data = eos_train) |>step_tokenize(text) |>step_stopwords(text) |>step_stem(text) |># ad hoc testing indicates that increasing max tokens makes a differencestep_tokenfilter(text, max_tokens =1000) |>step_tfidf(text)
It is computationally expensive. FindTopicsNumber_plot() shows the measures and labels them based on if th measures should be minimized or maximized.
library(ldatuning)results <-FindTopicsNumber( eos_dtm,topics =seq(from =2, to =82, by =10),# note: "Griffiths2004" does not work on Mac M1 chips because of Rmpfrmetrics =c("CaoJuan2009", "Arun2010", "Deveaud2014"),method ="Gibbs",control =list(seed =77),mc.cores =6L,verbose =TRUE)FindTopicsNumber_plot(results)


{kind=link}